Scientists studied optimal multi-impulse linear rendezvous via reinforcement learning
Multi-impulse orbital rendezvous is a classical spacecraft trajectory optimization problem, which has been widely studied for a long time. Numerical optimization methods, deeplearning (DL) methods, reinforcement learning (RL) methods have been proposed. However, for the numerical optimization methods, they need long computation time, and they are usually not valid for the many-impulse rendezvous case with the magnitude constraints. For the machine learning (ML) methods, the DL method needs large amounts of data, and the RL method has the weakness of low efficiency. Nevertheless, ML demonstrates more accurate predictions for the short-term horizon, whereas RL for the longer term. Combining the advantages of both, a policy can be pretrain differently. In a research paper recently published in Space: Science & Technology, researchers from Harbin Institute of Technology proposed a reinforcement learning-based approach to design the multi-impulse rendezvous trajectories in linear relative motions, enabling the rapid generation of rendezvous trajectories through the offline training and the on-board deployment.
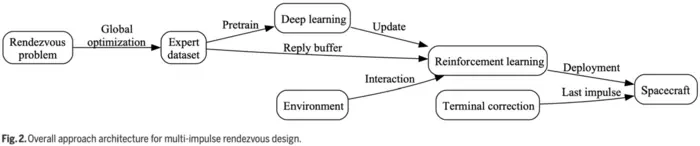
First, authors provide the mathematical model describing a multi-impulse linear rendezvous problem and the RL algorithms used, and present the RL-based approach to rendezvous design. For the multi-impulse linear rendezvous problem, the relative motion for rendezvous is typically represented by the 2-body linear relative motion equations. Based on the linear equations, constrained optimization is used to solve the multi-impulse rendezvous problems, where the optimization variables are the impulse vector and the impulse time. The objective function is the total velocity increment for the fuel-optimal orbital rendezvous problem, while the objective function is the rendezvous time for the time-optimal orbital rendezvous problem. In addition, the impulse magnitude constraints, the time constraints, and the terminal distance constraint are also formulated. For RL, the goal is to train a policy π(a|s) that learns how to map the states s and the actions a in order to maximize the reward signal ℛ(s,a) for an agent interacting with its environment. To this end, the multi-impulse rendezvous problem is considered as a fully observable Markov decision process (MDP). In this RL, the actor-critic (AC) architecture is adopted for its state-of-the-art performance on a wide variety of complex control problems. Moreover, the advantage-weighted AC (AWAC) algorithm is used to accelerate RL by using a smaller expert dataset. AWAC can always approach expert performance faster than SAC for all dataset sizes tested, and AWAC can approach a better performance with smaller expert datasets compared with IL. To sum up, assuming that the spacecraft can be maneuvered according to its current state, with Markovian properties, the rendezvous design is formulated as an RL problem. The state vector s is formulated to reflect the state of the spacecraft and relevant problem variables. The policy network π(a|s) outputs an action based on the state. The action vector a contains the impulse and the coasting period. ℛ, the reward at a single timestep for the fuel-optimal orbital rendezvous problem or the instantaneous reward of the MDP, is defined. In addition, in order to get a closer terminal distance, a semi-analytical method is used by combining with the RL approach. The overall algorithmic scheme is shown in Fig. 2.
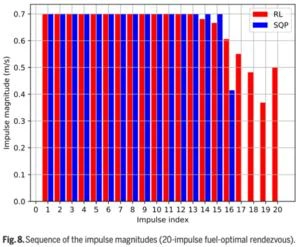
Then, authors examine the proposed method for rendezvous missions in four scenarios. As for fuel-optimal orbital rendezvous in the random initial states, the random eccentricity of the target orbit satisfies a uniform distribution in [0.65,0.75] and the perigee height of the target is set to be 500 km. The maximum number of maneuvers is set to be 6, and the impulse magnitude limit is set to be 5 m/s. An expert dataset of 1,000 trajectories generated by DE is used to speed up the training of RL, and results show that the algorithm using the expert dataset can converge in fewer timesteps. One hundred of experiments are done in random initial states with different maximum distances to evaluate the performance of the RL-based approach. Compared with the DE algorithm, the fuel consumption of the RL-based approach is increased by about 10%; however, the computation time is less than 0.1% of that of the DE algorithm. As for the fuel-optimal orbital rendezvous in the fixed initial state, a special case is used where both the target and the chaser are moving near a geostationary transfer orbit. Two cases are considered: (1) the 6-impulse rendezvous where the solution of the RL policy is compared with that of the DE, and (2) the 20-impulse rendezvous, where the control variables generated by the RL policy are used as initial values of the SQP for further optimization. Figure 8 illustrates the magnitude of each impulse in the 2 solutions. The last 3 impulses of the SQP solution are almost zero, i.e., the fuel-optimal orbital rendezvous is achieved with 16 impulses. In comparison, the RL-based solution has a more uniform variation of impulse magnitude. As for the time-optimal orbital rendezvous in the random initial states, the scenario parameters of the experiment are the same as those in the fuel-optimal orbital rendezvous. The RL-based approach requires only 0.02% of the computation time to obtain a feasible solution with only 15% less reward than the numerical optimization. As for the time-optimal orbital rendezvous in the fixed initial state, the 6-impulse and 20-impulse orbital rendezvous problems are also used for evaluation. Table 5 shows the coasting time and the velocity increment of each maneuver for both approaches. Since the policy network tends to learn general laws, the RL-based solution has a more uniform variation of control variables.
Finally, authors make the conclusions. Conclusion includes some concluding remarks. In this study, separate reward functions are designed for the fuel-optimal and time-optimal objectives. The numerical results show that the trained agents can design the optimal multi-impulse rendezvous maneuvers with different objectives at a random initial state. The proposed approach is effective for arbitrary multi-impulse rendezvous near elliptical orbits, especially in the case of a large number of impulses. The proposed approach can quickly produce feasible solutions that are slightly worse than the global optimization methods, making it an attractive choice in time-sensitive situations. The rendezvous trajectory generated by the trained agent can also be used as the initial value for further optimization. The offline training agent can be deployed on spacecraft due to its short computation time advantage.
END