Enhancing automatic image cropping models with advanced adversarial techniques
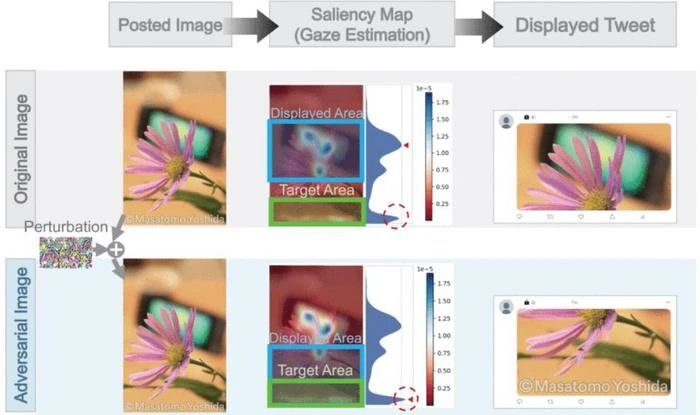
Image cropping is an essential task in many contexts, right from social media and e-commerce to advanced computer vision applications. Cropping helps maintain image quality by avoiding unnecessary resizing, which can degrade the image and consume computational resources. It is also useful when an image needs to conform to a predetermined aspect ratio, such as in thumbnails. Over the past decade, engineers around the world have developed various machine learning (ML) models to automatically crop images. These models aim to crop an input image in a way that preserves its most relevant parts.
However, these models can make mistakes and exhibit biases that, in the worst cases, can put users at legal risk. For example, in 2020, a lawsuit was filed against X (formerly Twitter) because its automatic cropping function hid the copyright information in a retweeted image. Therefore, it is crucial to understand the reason image cropping ML models fail so as to train and use them accordingly and avoid such problems.
Against this background, a research team from Doshisha University, Japan, set out to develop new techniques to generate adversarial examples for the task of image cropping. As explained in their latest paper, published in IEEE Access on June 17, 2024, their methods can introduce imperceptible noisy perturbations into an image to trick models into cropping regions that aligns with user intentions, even if the original model would have missed it. Doctoral student Masatomo Yoshida, the first author and lead researcher of the study, explains their motivation by saying, “To the best of our knowledge, there is very little research on adversarial attacks on image cropping models, as most previous research has focused on image classification and detection. These models need to be refined to ensure they respect user intentions and eliminate biases as much as possible while cropping images.” Masatomo Yoshida and Haruto Namura from the Graduate School of Science and Engineering, Doshisha University, Kyoto, Japan and Masahiro Okuda is from the Faculty of Science and Engineering at Doshisha University were also a part of the study.
The researchers developed and implemented two distinct approaches for generating adversarial examples — a white-box approach and a black-box approach. The white-box method, requiring access to the internal workings of the target model, involves iteratively calculating perturbations to input images based on the model’s gradients. By employing a gaze prediction model to identify salient points within an image, this approach manipulates gaze saliency maps to achieve effective adversarial examples. It significantly reduces perturbation sizes, achieving a minimum size 62.5% smaller than baseline methods across an experimental image dataset.
The black-box approach utilizes Bayesian optimization to effectively narrow the search space and target specific image regions. Similar to the white-box strategy, this approach involves iterative procedures based on gaze saliency maps. Instead of using internal gradients, it employs a tree-structured Parzen estimator to select and optimize pixel coordinates that influence gaze saliency, ultimately producing desired adversarial images. Notably, black-box techniques are more broadly applicable in real-world scenarios and hold greater relevance in cybersecurity contexts.
Both approaches show promise based on experimental outcomes, as graduate student Haruto Namura, a participant in the study, explains, “Our findings indicate that our methods not only surpass existing techniques but also show potential as effective solutions for real-world applications, such as those on platforms like Twitter.”
Overall, this study represents a significant advancement toward more reliable AI systems, crucial for meeting public expectations and earning their trust. Enhancing the efficiency of generating adversarial examples for image cropping will propel research in ML and inspire solutions to its pressing challenges. As Professor Masahiro Okuda, advisor to Namura and Yoshida, concludes, “By identifying vulnerabilities in increasingly deployed AI models, our research contributes to the development of fairer AI systems and addresses the growing need for AI governance.”
We will surely be keeping an eye out for further progress in this area!
About Masatomo Yoshida from Doshisha University, Japan
Masatomo Yoshida received his B.E. and M.E. degrees from Doshisha University, Kyoto, Japan, in 2021 and 2023, respectively. He is currently pursuing a Ph.D. degree in engineering at the Graduate School of Science and Engineering of Doshisha University. His research interests include analyzing spatio-temporal time series data, image processing, deep learning, and adversarial examples. He was awarded the Support for Pioneering Research Initiated by the Next Generation (SPRING) Scholarship by the Japan Science and Technology Agency (JST). Additionally, he received an award in a local photography contest held in Kyoto in 2015.
Funding information
This work was supported in part by the Japan Science and Technology Agency (JST) Support for Pioneering Research Initiated by the Next Generation (SPRING) under Grant JPMJSP2129, in part by the Japan Society for the Promotion of Science (JSPS) KAKENHI under Grant 23K11174, and in part by the Ministry of Education, Culture, Sports, Science and Technology (MEXT), Japan, Promotion of Distinctive Joint Research Center Program under Grant JPMXP 0621467946.
Media contact:
Organization for Research Initiatives & Development
Doshisha University
Kyotanabe, Kyoto 610-0394, JAPAN
E-mail:jt-ura@mail.doshisha.ac.jp
END